Program Flow
The script engine executes based on the structure of the destination Data Definition, by running through its datasets and fields and executing the events.
This is termed the Program Flow, and is the order in which the events are executed by the script engine. This happens in a pre-determined order, however it is possible for the user to control this order of execution with special functions within the script.
To describe the Program Flow, it is best to illustrate it with an example. During execution, the Statelake Map converts a source Data Definition into a destination Data Definition. For the purpose of this example, we use a source Data Definition that is reading from an Informix database, and a destination Data Definition that is connected to a MSSQL database.
Example Of Program Flow
Source Data Definition
This source Data Definition represents a list of orders, and contains three datasets ORD_HEAD, ORD _LINE, and LINE_MESG.
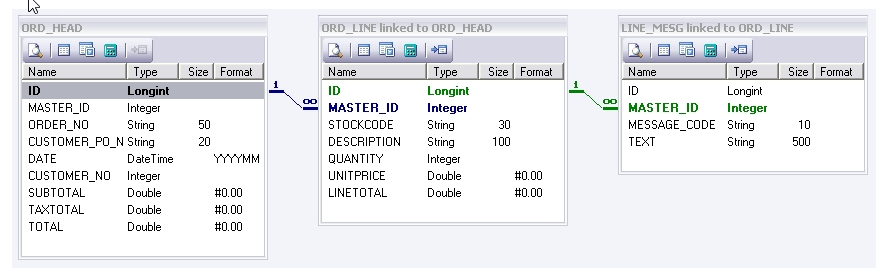
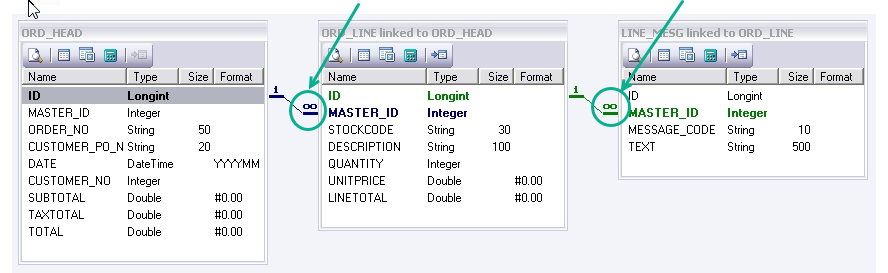
By the symbols next to the linking line you can determine the hierarchy and therefore which is the child dataset - the infinity sign is the child as indicated below. In this case LINE_MESG is the child of ORD_LINE which in turn is the child of ORD_HEAD.
Each of the orders identified by this Data Definition has one or more lines, and each line has one or more messages. In this example, there are 10 orders in total within the Data Definition, - 10 ORD_HEAD records each with 5 ORD_LINE records, each with 2 LINE_MESG records.
Destination Data Set
The destination Data Definition again represents a list of orders and contains three datasets ORDER_HEADER, ORDER _LINE, and LINE_MESSAGES.
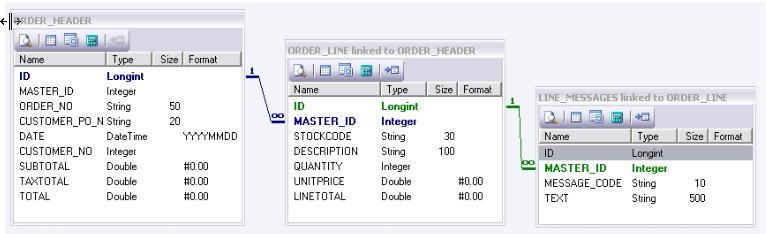
For simplicity these destination datasets are very similar to those in the source, except they have slightly different names.
This destination Data Definitions therefore will contain a list of orders, with each order having one or more lines, and each line having one or more messages.
Execution Of The Map
Until the mapping has occurred, this destination data set is empty. The purpose of the Map is to fill the data set with details taken from the source data set and save it somewhere.
Within the Map editor, these Data Definitions are shown in a tree format representative of their hierarchy. The source Data Definition is on the left, and the destination Data Definition is on the right.

The script engine is based off the destination Data Definition, and therefore, when the Map executes the following program flow occurs.
The ORDER_HEADER destination dataset is processed - the events entered in the event script against the dataset fire, and then the events against each of its fields are fired. This results in one record being created in the ORDER_HEADER destination dataset.
The ORDER_LINE destination dataset is processed - the events entered in the event scripting against the dataset fire, which is followed by the events against each of its fields being fired. This results in one record being created in the ORDER_LINE destination dataset. This record is linked to the ORDER_HEADER destination dataset record.
The LINE_MESSAGES destination dataset is processed - the events entered in the event scripting against the dataset fire, and then the events against each of its fields are fired. This results in one record being created in the LINE_MESSAGES destination dataset, and this record is linked to the ORDER_LINE destination data set record.
At this point the processing finishes.
However, the processing doesn't necessary have to finish there.
What happens next depends on whether the LinkedData event is set for any of the datasets. For more information about this and other event types, please refer to Events.
The LinkedData event is a special event that indicates whether a source dataset is linked to this dataset. When there is no LinkedData event, the destination dataset is processed once and therefore one record is created as a result.
In this example, the source dataset ORD_HEAD is linked to the destination dataset ORDER_HEADER. The script engine will now scroll through the records of the linked source dataset until it comes to the end. If there is a child dataset, it processes that first before scrolling to the next record in the source.
A dataset has only one active record at a time. The script engine determines the end of the dataset when it sees no more records, however the script engine only sees the records in the child dataset that match to the parent dataset.
When the mapping first starts, record 1 of the ORD_HEAD source dataset is active. The script engine only sees its 5 ORD_LINE source dataset records, of which the first one of these is active - meaning the engine only sees the 2 LINE_MESG source dataset records for that single active ORD_LINE record.
Remember that in this example, the source dataset has 10 orders within it, and each of these orders have 5 lines, and each of these 5 lines have 2 messages each.
The following illustrates only the program flow for processing the first source dataset ORD_HEAD record.
The ORDER_HEADER destination dataset is opened - record 1 from the source dataset ORD_HEAD is translated and a record is created in destination dataset ORDER_HEADER.
The ORDER_LINE destination dataset is opened - record 1 from the source dataset ORD_LINE is translated and a record is created in destination dataset ORDER_LINE.
The LINE_MESSAGES destination dataset is opened - record 1 from the source dataset LINE_MESG is translated and a record is created in destination dataset LINE_MESSAGES.
The LINE_MESSAGES destination dataset is accessed again - record 2 from the source dataset LINE_MESG is translated and another record is created in the destination dataset LINE_MESSAGES. Because the destination dataset LINE_MESSAGES has no child datasets itself, but it is linked to the source LINE_MESG dataset, it keeps on processing until all of the LINE_MESG records have been processed - and there are 2 messages for the currently processed order line.
The ORDER_LINE destination dataset is again accessed - and record 2 from the source ORD_LINE dataset is translated and another record is created in the destination dataset ORDER_LINE.
The LINE_MESSAGES destination dataset is accessed again - record 1 from the source dataset LINE_MESG (for order 2) is translated and a record is created in the destination dataset LINE_MESSAGES. Remember that this is the first message record of the second order line.
The LINE_MESSAGES destination dataset is again accessed - and record 2 from the source dataset LINE_MESG is translated and another record is created in the destination dataset LINE_MESSAGES. This is the second message record for the second order line.
The destination dataset ORDER_LINE dataset is again accessed - record 3 from the source dataset ORD_LINE is translated and a record is created in destination dataset ORDER_LINE.
. . . . and so on . . .
Eventually, after the 5 source dataset ORDER_LINE records have each been processed, the source dataset ORDER_HEADER record is again accessed, and record 2 from ORD_HEAD is translated and a record is created in destination dataset ORDER_HEADER.
And the whole process occurs again until all records have been processed from the linked source datasets, as illustrated by this PFD.
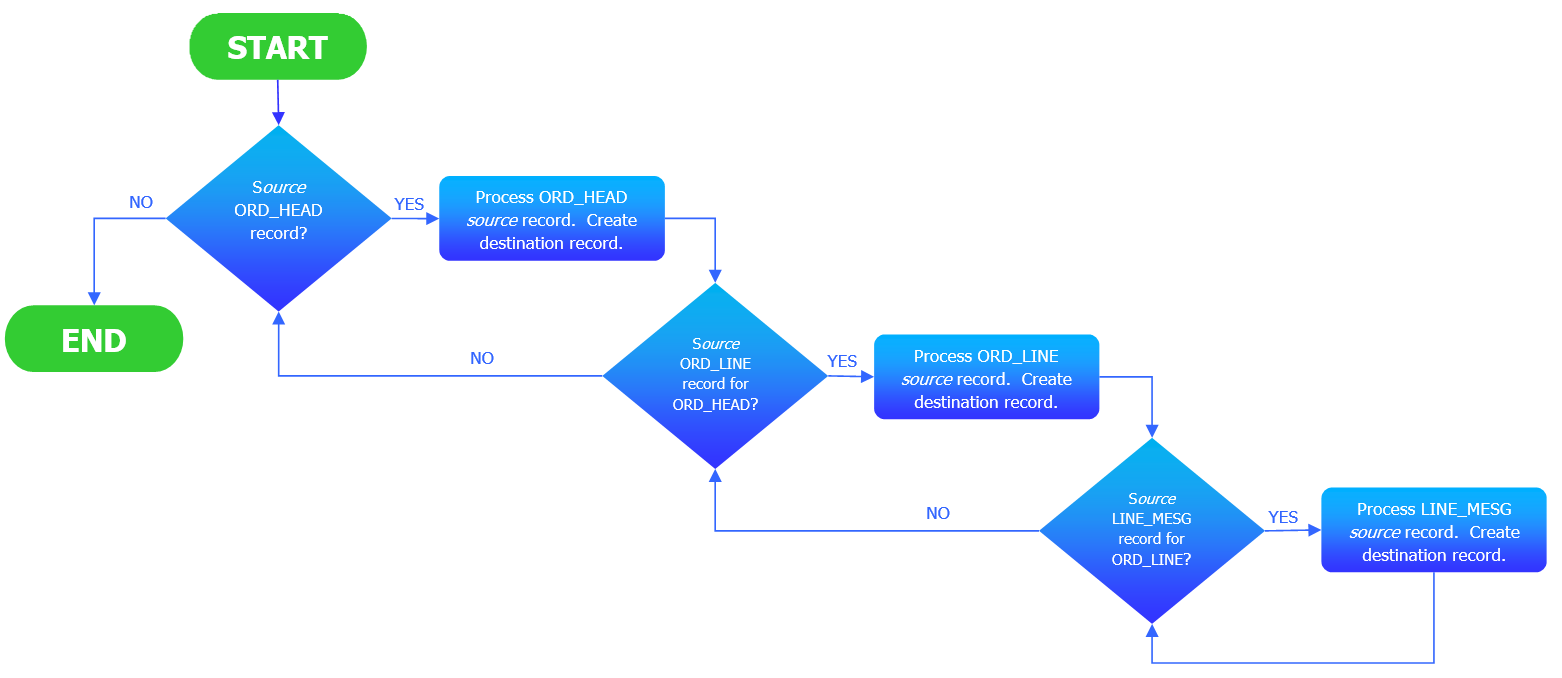
In essence, the first ORD_HEAD record is processed, then each of its ORD_LINE records, and each of the LINE_MESG records for each line. Eventually the next ORD_HEAD is processed and the loop continues until no data is left in the source.
The user can modify this program flow through special functions in the script. These can be reviewed via Program Control Functions.